System design has become an essential skillset among engineers building systems for large businesses that rely on on state of the art technologies to drive their operations and processes. Whether you’re designing an application or large scale distributed system, understanding of the fundamental concepts will help take your career to the next level. This article provides a comprehensive primer on the core ideas and knowledge needed to succeed in a system design interview.
What is System Design?
System design refers to the process of defining the architecture, components, modules, interfaces, and data required to satisfy specified requirements. It involves breaking down complex problems in manageable pieces and designing how those components interact with each other. In essence, its about creating a blueprint for a system that is scalable, reliable, maintainable, and efficient.
Why is System Design Important?
There are four primary quality attributes a system must have in order to meet business goals and provide a product that can thrive in a competitive marketplace. These attributes include:
- Scalability: As applications grow in popularity, they must be able to handle an increasing number of users and data. A well-designed system can scale seamlessly to accommodate growth without sacrificing performance.
- Reliability: A reliable system is one that performs consistently and can recover from failures without significant downtime. This is critical for maintaining user trust and ensuring that the system is always available.
- Maintainability: Systems evolve over time. A well-designed system is easy to maintain, with clear separation of concerns, modularity, and well-documented components, making it easier to implement changes and fix issues.
- Efficiency: Efficient systems make optimal use of resources, such as CPU, memory, and network bandwidth. This ensures that the system can perform well even under heavy load.
Key Concepts in System Design
Scalability and Performance
As a system continues to grow, it must be able to handle increasing amounts of traffic and large workloads. Scalability is essential to ensuring that your applications can continue to function properly under increased demand. Two primary ways to achieving reliability and availability of your application is horizontal and vertical scaling.
Horizontal Scaling (Scaling Out)
Horizontal scaling involves adding more machines or servers to system in order to handle increased load. Instead of upgrading a single service, you add more servers to share the workload. These machines can have their traffic distributed among them through the use of load balancers that process traffic and direct it in an efficient manner to the correct service. Horizontal scaling is preferred for large-scale systems because it offers better fault tolerance and flexibility.
Pros:
- Scalability: Theoretically, you can scale out indefinitely by adding more machines.
- Fault Tolerance: If one machine fails, others can take over, making the system more resilient.
- Cost-Effectiveness: Instead of investing in high-end hardware, you can use commodity hardware and scale by adding more machines.
Cons:
- Complexity: Managing a distributed system is more complex. It requires efficient load balancing, synchronization, and possibly dealing with issues like data consistency and latency.
- Network Overhead: Communication between machines can introduce additional overhead, especially if the system is not optimized.
- Data Consistency: Keeping data consistent across multiple nodes can be challenging, especially in distributed databases.
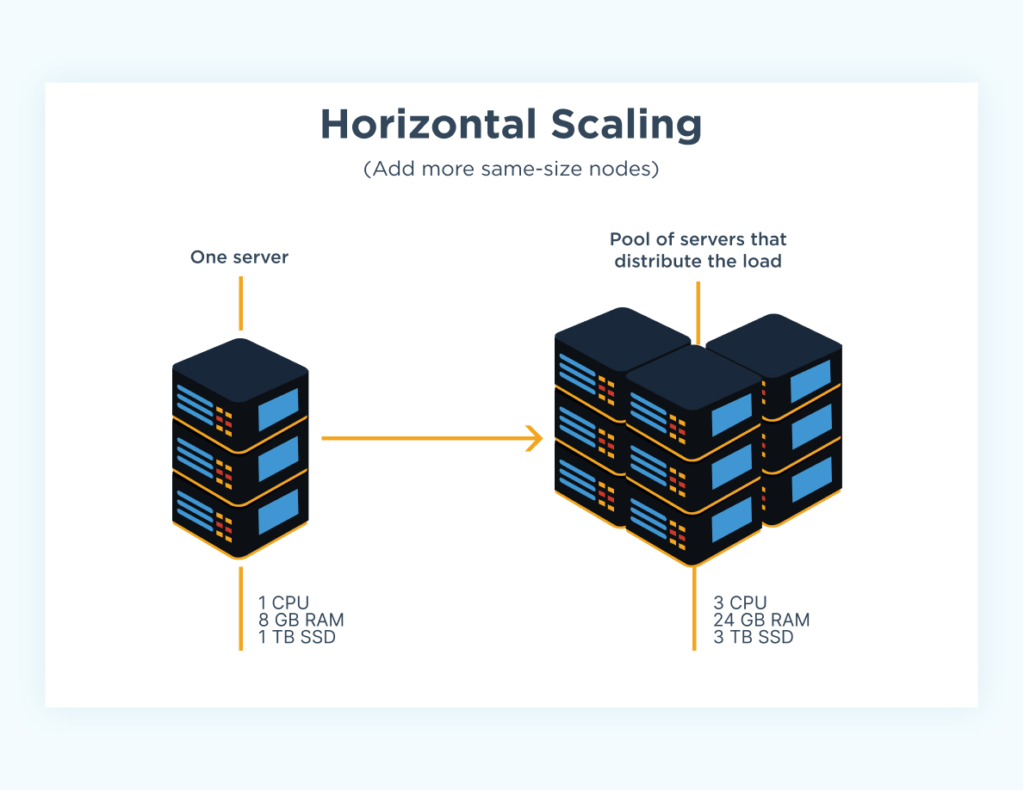
Source: https://www.cloudzero.com/blog/horizontal-vs-vertical-scaling/
Vertical Scaling (Scaling Up)
Vertical scaling involves adding more resources (CPU, memory, storage, etc.) to an existing server or system to handle increased load. This is like upgrading a computer with more powerful components to improve its performance. This was the traditional approach to increasing reliability in a system, but is much less cost effective than horizontal scaling.
Pros:
- Simplicity: It’s often easier to manage since you’re dealing with a single system.
- Consistency: All your data and processes are centralized in one place, reducing the complexity of synchronization or load balancing.
- Maintenance: Less administrative overhead because you’re managing fewer machines.
Cons:
- Limits: There’s a physical limit to how much you can scale vertically. Hardware has maximum capabilities, and after reaching this limit, further upgrades may not be possible or cost-effective.
- Single Point of Failure: If the system goes down, everything goes down since all resources are tied to a single machine.
- Cost: High-end hardware can be very expensive.
Example: Upgrading a server’s CPU from 4 cores to 16 cores, increasing its RAM from 16GB to 64GB, or adding more storage space to handle more data.
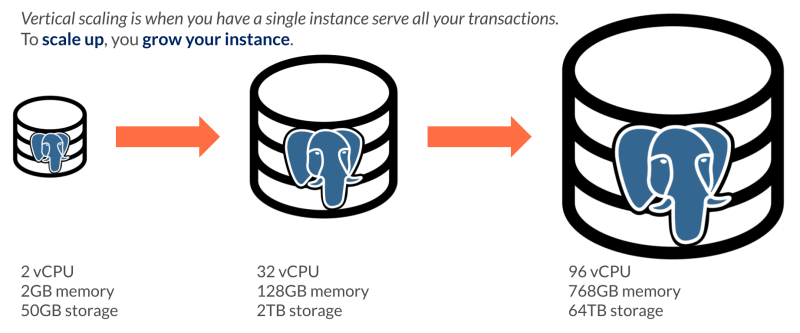
Source: https://dev.to/yugabyte/horizontal-scaling-vs-vertical-scaling-for-sql-what-s-the-difference-kn2
Load Balancing
Load balancing refers to the process of distributing network or application traffic across multiple servers. By spreading the workload evenly, load balancing ensures that no single server becomes overwhelmed with too many requests. This is crucial for maintaining high availability, reliability, and performance of services.
Key Concepts in Load Balancing
- Load Balancer:
- A load balancer is a device or software application that sits between clients (e.g., users or applications) and backend servers. It receives incoming traffic and forwards it to one of the available servers based on specific algorithms.
- Load balancers can operate at different levels of the OSI model:
- Layer 4 (Transport Layer): Distributes traffic based on information like IP address and TCP/UDP ports.
- Layer 7 (Application Layer): Makes decisions based on the content of the message, such as HTTP headers, cookies, or URLs.
- Backend Servers (Nodes):
- These are the servers that actually process the requests. The load balancer distributes incoming requests to these servers.
- Backend servers could be web servers, application servers, database servers, etc.
Load Balancing Algorithms
Different load balancing algorithms determine how traffic is distributed among the servers:
- Round Robin:
- Traffic is distributed evenly across all servers in a sequential manner. For example, the first request goes to Server 1, the second to Server 2, and so on.
- Pros: Simple to implement.
- Cons: Does not consider the current load or capacity of the servers.
- Least Connections:
- The request is sent to the server with the fewest active connections. This is useful when each request generates a similar amount of load.
- Pros: Helps balance the load more effectively when requests vary in duration.
- Cons: May not be as effective if servers have different capacities.
- IP Hash:
- The client’s IP address is hashed to determine which server should handle the request. This method is often used to maintain session persistence, ensuring that the same client is directed to the same server.
- Pros: Maintains session persistence.
- Cons: Can lead to uneven distribution if IPs are not uniformly distributed.
- Weighted Round Robin:
- Similar to Round Robin, but assigns a weight to each server based on its capacity. Servers with higher capacity get more requests.
- Pros: More efficient use of server resources.
- Cons: Requires manual configuration of server weights.
- Least Response Time:
- Requests are sent to the server with the lowest response time and the fewest active connections.
- Pros: Optimizes for the quickest response time.
- Cons: Requires constant monitoring of server performance.
Types of Load Balancers
- Hardware Load Balancers:
- These are dedicated physical devices designed specifically for load balancing. They offer high performance and advanced features but can be expensive.
- Examples: F5 BIG-IP, Citrix ADC (NetScaler).
- Software Load Balancers:
- These are software applications that run on general-purpose hardware. They offer flexibility and are cost-effective.
- Examples: Nginx, HAProxy, Apache Traffic Server.
- Cloud Load Balancers:
- These are managed load balancing services provided by cloud platforms. They are scalable, easy to set up, and integrated with other cloud services.
- Examples: AWS Elastic Load Balancer (ELB), Google Cloud Load Balancing, Azure Load Balancer.
Benefits of Load Balancing
- High Availability:
- Load balancing ensures that if one server fails, traffic is redirected to other healthy servers, thereby maintaining service availability.
- Scalability:
- Load balancers allow for horizontal scaling, meaning you can add more servers to handle increased traffic without downtime.
- Improved Performance:
- By distributing traffic across multiple servers, load balancing reduces the load on each server, leading to faster response times.
- Redundancy:
- Load balancing adds redundancy to your system, reducing the risk of a single point of failure.
- Security:
- Load balancers can also enhance security by hiding the IP addresses of backend servers, providing SSL termination, and protecting against Distributed Denial of Service (DDoS) attacks.
Challenges in Load Balancing
- Data Consistency:
- In distributed systems, ensuring that data remains consistent across all servers can be challenging, especially if requests are distributed across multiple servers.
- Latency:
- Load balancers themselves can become a bottleneck if not properly configured, adding latency to the system.
- Health Monitoring:
- Load balancers need to continuously monitor the health of backend servers to make intelligent decisions. This requires a well-designed monitoring system to detect and react to failures in real-time.
Real-World Use Cases
- Web Applications:
- For high-traffic websites, load balancers distribute incoming HTTP requests across multiple web servers to ensure the site remains responsive.
- E-commerce Platforms:
- During peak shopping seasons, e-commerce platforms use load balancers to distribute traffic among servers, ensuring customers can browse and purchase products without delays.
- Cloud Services:
- Cloud providers use load balancing to manage traffic across their data centers, providing scalable and reliable services to users worldwide.
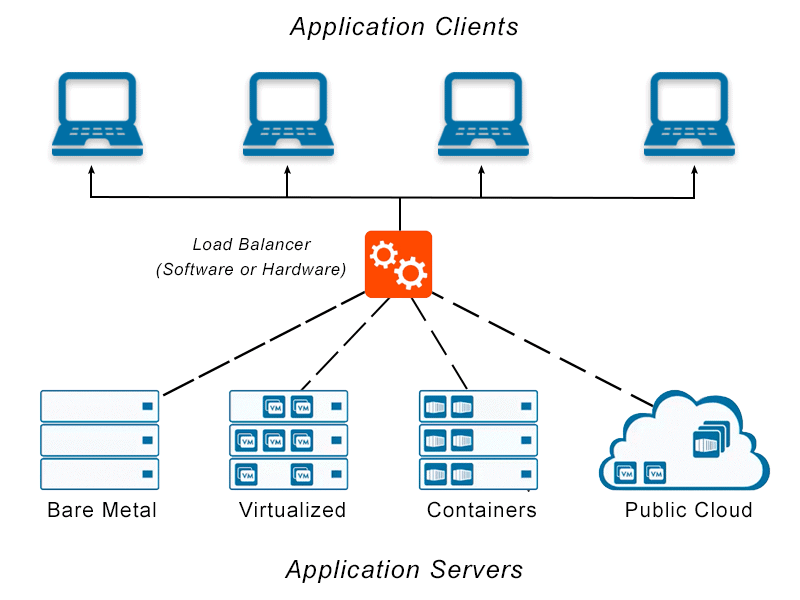
Source: https://avinetworks.com/glossary/load-balancer/
Caching
Caching involves storing a copy of data in a fast-access storage layer, called the cache, so that future requests for that data can be served more quickly. The data in the cache might be copies of files, results of database queries, web pages, or other information that is computationally expensive to retrieve or generate. Cached data is often stored in memory for fast access times.
Key Concepts
- Cache Layer:
- The cache layer is the temporary storage where data is stored. It can exist in various forms, such as in-memory storage (RAM), on-disk storage, or even distributed across multiple servers.
- Cache Hit and Cache Miss:
- Cache Hit: Occurs when the requested data is found in the cache, allowing the system to serve the data directly from the cache.
- Cache Miss: Occurs when the requested data is not found in the cache, forcing the system to retrieve the data from the original source and potentially store a copy in the cache for future use.
- Eviction Policy:
- Because cache storage is typically limited, there needs to be a strategy for deciding which data to remove when the cache is full. Common eviction policies include:
- Least Recently Used (LRU): Removes the least recently accessed items first.
- First In, First Out (FIFO): Removes the oldest items first.
- Least Frequently Used (LFU): Removes the items accessed least frequently.
- Random Replacement: Randomly removes items from the cache.
- Because cache storage is typically limited, there needs to be a strategy for deciding which data to remove when the cache is full. Common eviction policies include:
- Cache Invalidation:
- Invalidation refers to the process of removing outdated or incorrect data from the cache. This is crucial for ensuring that the cache serves up-to-date and accurate information. Invalidation can be triggered by changes in the underlying data or by the expiration of a time-to-live (TTL) value.
Types of Caching
- Memory Caching (In-Memory Caching):
- Data is stored in the system’s RAM, providing extremely fast access times. This is ideal for data that is frequently accessed and doesn’t require persistence.
- Examples: Redis, Memcached.
- Disk Caching:
- Data is stored on disk, which is slower than memory caching but allows for larger storage capacities. Disk caching is often used when the data is too large to fit in memory.
- Examples: Browser caching on disk, disk-based caching systems like Varnish.
- Database Caching:
- Frequently queried data from a database is stored in a cache to reduce the load on the database and improve query response times.
- Examples: Query results caching, caching entire tables or objects.
- Web Caching:
- Web content, such as HTML pages, images, and scripts, is cached to reduce server load and improve load times for users.
- Examples: Content Delivery Networks (CDNs), browser caching.
- Distributed Caching:
- A caching system spread across multiple servers or locations to handle large-scale applications and ensure high availability and fault tolerance.
- Examples: Distributed Redis, Amazon ElastiCache.
Benefits of Caching
- Performance Improvement:
- Caching significantly reduces the time required to retrieve data, leading to faster response times and improved application performance.
- Reduced Latency:
- By serving data from a cache, the system can reduce the latency that occurs when fetching data from slower storage or remote servers.
- Lower Resource Consumption:
- Caching reduces the load on backend systems like databases or APIs, which can lead to lower operational costs and better resource utilization.
- Scalability:
- By offloading requests to the cache, systems can handle more concurrent users and requests without overloading the backend infrastructure.
- Availability:
- Cached data can be served even if the original data source is unavailable, increasing the overall availability of the system.
Challenges and Considerations in Caching
- Cache Invalidation:
- Ensuring that the cache reflects the most up-to-date data is a critical challenge. Stale data in the cache can lead to inconsistencies and incorrect responses.
- Cache Coherence:
- In distributed caching systems, maintaining consistency across multiple caches can be complex. Cache coherence protocols are needed to ensure that all caches reflect the same data.
- Memory Consumption:
- Caching, especially in-memory caching, consumes resources like RAM, which is limited. Proper management and optimization are required to avoid running out of memory.
- Security Concerns:
- Sensitive data stored in a cache can be a security risk if not properly protected. Access controls and encryption may be necessary to secure cached data.
- Cache Warming:
- When a system starts up or after a cache is cleared, the cache needs to be populated, which can temporarily lead to higher latency and load on the backend systems.
Real-World Use Cases
- Web Browsers:
- Browsers cache static resources like images, CSS files, and JavaScript files locally on the user’s device. This reduces the time required to load web pages on subsequent visits.
- Content Delivery Networks (CDNs):
- CDNs cache web content across multiple geographically distributed servers. This allows users to access content from a server closer to them, reducing latency and improving load times.
- Database Systems:
- Databases often implement query caching to store the results of frequently run queries. This reduces the need to recompute the result and lightens the load on the database.
- API Response Caching:
- APIs cache responses to common queries, reducing the need to perform the same computation or database query multiple times.
- Machine Learning Models:
- In machine learning systems, caching is used to store precomputed model predictions or intermediate results, speeding up the inference process.

Source: https://medium.com/enjoy-algorithm/caching-system-design-concept-500134cff300
Reliability
Reliability in system design refers to the ability of a system to consistently perform its intended functions without failure over a specified period of time. In the context of software systems, reliability is crucial because it directly impacts user trust, system availability, and business continuity. Let’s explore the key aspects of reliability in system design, how it’s achieved, the CAP theorem, and why reliability matters.
The CAP Theorem, also known as Brewer’s Theorem, states that in a distributed system, it is impossible to simultaneously guarantee all three of the following properties: Consistency (every read receives the most recent write or an error), Availability (every request receives a response, even if some nodes are down), and Partition Tolerance (the system continues to function despite network partitions). Due to this inherent trade-off, a distributed system can only fully achieve two of these three properties at any given time.
Availability
- Definition: Availability is the percentage of time a system is operational and accessible when needed. High availability is critical for systems that users rely on around the clock, such as e-commerce platforms, financial services, or cloud services.
- How to Achieve:
- Redundancy: Implementing redundant components (e.g., multiple servers, databases) ensures that if one component fails, others can take over without interrupting the service.
- Load Balancing: Distributing traffic across multiple servers helps prevent any single server from becoming a point of failure.
- Failover Mechanisms: Automatic switching to a backup system in case of failure ensures continuous operation.
Fault Tolerance
- Definition: Fault tolerance is the ability of a system to continue operating properly in the event of the failure of some of its components. A fault-tolerant system anticipates potential failures and is designed to handle them gracefully.
- How to Achieve:
- Error Detection and Correction: Implement mechanisms that detect errors and correct them before they cause system failure.
- Graceful Degradation: Design the system to reduce functionality when a component fails, rather than completely shutting down.
- Replicas: Use data and component replicas so that if one fails, others can serve the same function.
Consistency
- Definition: Consistency ensures that all parts of the system reflect the same data at any given time. In distributed systems, maintaining consistency across different nodes can be challenging, especially when dealing with network partitions or concurrent updates.
- How to Achieve:
- Data Replication: Ensure that data changes are propagated to all replicas in a consistent manner.
- Strong vs. Eventual Consistency: Choose the appropriate consistency model based on the system’s needs. Strong consistency guarantees that all nodes see the same data simultaneously, while eventual consistency allows temporary discrepancies that are resolved over time.
Resilience
- Definition: Resilience is the ability of a system to recover quickly from failures and return to normal operation. This includes recovering from hardware failures, software bugs, or unexpected user behaviors.
- How to Achieve:
- Monitoring and Alerts: Implement continuous monitoring to detect issues in real-time and set up alerts for immediate response.
- Automatic Recovery: Design systems with self-healing capabilities, such as automated failover, restart, or rollback to a previous stable state.
- Backup and Restore: Regularly back up data and ensure that restoration procedures are tested and reliable.
Reliability Engineering Practices
- Testing and Validation: Regularly test the system under different conditions (e.g., load testing, fault injection) to identify potential weaknesses and ensure that reliability measures are effective.
- Chaos Engineering: A practice of intentionally introducing failures into the system to test its resilience and fault tolerance. This helps teams understand how their system behaves under stress and identify areas for improvement.
- Design for Failure: Assume that components will fail and design the system to handle these failures without impacting overall functionality. This includes building in redundancy, using reliable messaging systems, and implementing comprehensive error-handling mechanisms.
Why Reliability Matters in System Design
- User Trust and Satisfaction: Users expect systems to be available and reliable. Frequent downtimes or data inconsistencies can lead to frustration, loss of trust, and ultimately, loss of customers.
- Business Continuity: For many businesses, system downtime directly translates to lost revenue. Ensuring reliability means minimizing downtime and maintaining service continuity, which is critical for business operations.
- Compliance and Legal Requirements: In some industries, regulatory requirements mandate a certain level of system reliability and availability. Failing to meet these standards can result in legal penalties and damage to the business’s reputation.
- Competitive Advantage: Reliable systems can provide a competitive edge by ensuring that services are consistently available and performing well, which can be a key differentiator in a crowded market.
Example: Reliability in a Real-World System
Consider an online payment system used by millions of users worldwide. Reliability is paramount because any downtime or transaction failure could result in financial losses and damage to the company’s reputation.
- High Availability: The system is designed with multiple data centers across different geographical locations. If one data center experiences an outage, traffic is automatically redirected to another.
- Fault Tolerance: The system uses redundant servers and databases. Transactions are processed using distributed databases with strong consistency models to ensure that all records are accurate and up-to-date.
- Resilience: Continuous monitoring detects any abnormal spikes in transaction failures. Automated scripts are in place to restart services or roll back faulty deployments without affecting users.
- Testing: The system undergoes regular load testing and chaos engineering exercises to simulate potential failures and ensure that the system can handle them gracefully.
Database Design
The goal of database design is to structure your data efficiently and logically to support the needs of applications and users. A well-designed database minimizes redundancy and improves data integrity.
Normalization
This is the process of organizing data to reduce redundancy and improve data integrity. The idea is to divide a database into two or more tables and define relationships between the tables to eliminate redundancy. Normalization helps in reducing data anomalies and improving data integrity, but in practice, sometimes denormalization is applied for performance reasons, especially in read-heavy systems.
Normal Forms: There are several “normal forms” (NF), each with specific rules:
- First Normal Form (1NF): Ensures that the table has a primary key and that each column contains atomic (indivisible) values. There should be no repeating groups or arrays.
- Second Normal Form (2NF): Achieved when the table is in 1NF and all non-key attributes are fully functional dependent on the primary key. This means that attributes must depend on the whole key, not just part of it (for composite keys).
- Third Normal Form (3NF): Achieved when the table is in 2NF and all the attributes are functionally dependent only on the primary key, not on other non-key attributes. This eliminates transitive dependencies.
- Boyce-Codd Normal Form (BCNF): A stricter version of 3NF, which handles some specific cases where 3NF might still allow anomalies.
- Fourth Normal Form (4NF): Deals with multi-valued dependencies. It requires that a table is in BCNF and has no multi-valued dependencies.
- Fifth Normal Form (5NF): Deals with cases where information can be reconstructed from smaller pieces of information and ensures that there are no join dependencies.
SQL vs. NoSQL Databases
SQL Databases
- Structured Query Language (SQL): SQL databases use SQL for querying and managing data. They are typically relational databases and follow a schema that defines the structure of the data.
- Characteristics:
- Schema-Based: Data is organized into tables with predefined schemas (tables, columns, data types).
- ACID Transactions: Support for Atomicity, Consistency, Isolation, and Durability, ensuring reliable transactions.
- Examples: MySQL, PostgreSQL, Oracle, Microsoft SQL Server.
NoSQL Databases
- Not Only SQL (NoSQL): NoSQL databases are designed for more flexible data models and are often used for large-scale data and real-time applications.
- Characteristics:
- Schema-Less: Data is stored in formats like documents, key-value pairs, graphs, or wide-columns. Schemas can be dynamic.
- Scalability: Often better suited for horizontal scaling, meaning they can handle large amounts of data and high traffic by distributing the load across many servers.
- Examples: MongoDB (document-oriented), Redis (key-value), Neo4j (graph), Cassandra (wide-column).
When to Use Each:
- SQL: Best for applications requiring complex queries and transactions, where data integrity and consistency are crucial.
- NoSQL: Ideal for applications with rapidly changing schemas, high-volume, or unstructured data, and those needing high scalability.
Sharding
This is a technique used to distribute data across multiple database servers to improve performance and scalability. Each server, or shard, holds a subset of the data. Sharding is often used in conjunction with replication (duplicating data across multiple servers) to ensure high availability and fault tolerance.
How Sharding Works
- Horizontal Partitioning: Data is divided into chunks, and each chunk is stored on a different server. For example, a user database might be sharded based on user ID ranges or geographic location.
- Shard Key: The key used to determine how data is distributed across shards. It should be chosen carefully to ensure an even distribution of data and queries.
- Benefits:
- Scalability: Handles larger datasets and higher loads by distributing the workload.
- Performance: Reduces the load on individual servers and can improve query response times.
- Challenges:
- Complexity: Increases complexity in querying and managing data.
- Consistency: Maintaining data consistency across shards can be more complex.
Source: https://gochronicles.com/database-design/
Networking and Communication
At a high level, networking involves connecting computers and systems to share resources and data. It includes understanding protocols, data transmission methods, and network topologies.
- Protocols: Set of rules for data communication. Common protocols include:
- HTTP/HTTPS: For web communications.
- TCP/IP: Core protocol suite for most internet communications.
- UDP: User Datagram Protocol, used for low-latency communications where speed is crucial, but reliability is not.
- Data Transmission: Involves breaking data into packets, sending them over the network, and reassembling them at the destination.
- Topologies: Different ways to arrange network devices, such as star, ring, mesh, and hybrid.
APIs and Microservices
APIs (Application Programming Interfaces):
APIs allow different software systems to communicate with each other. They define a set of rules and protocols for interacting with a service or application.
- Types:
- RESTful APIs: Use HTTP requests to GET, POST, PUT, DELETE data. They are stateless and use standard HTTP methods.
- SOAP APIs: Use XML-based messaging protocol. More rigid and often used in enterprise environments.
- GraphQL: Allows clients to request specific data from an API, rather than receiving a fixed structure.
Microservices
Microservices is an architectural style where an application is composed of small, loosely coupled services that are independently deployable. Each microservice handles a specific business function.
- Characteristics:
- Decentralized Data Management: Each service manages its own data.
- Autonomy: Services can be developed, deployed, and scaled independently.
- Communication: Typically involves APIs for inter-service communication.
- Benefits:
- Scalability: Scale individual services as needed.
- Flexibility: Different services can use different technologies and frameworks.
- Resilience: Failure in one service doesn’t necessarily affect others.
Message Queues and Event-Driven Architectures
Message Queues
- Definition: A message queue is a communication method used in asynchronous messaging. It allows different parts of a system to communicate by sending messages to a queue, which are then processed by other components.
- Characteristics:
- Asynchronous Communication: Senders and receivers do not need to interact in real-time.
- Decoupling: Components can operate independently, improving system resilience.
- Persistence: Messages can be stored until they are processed, improving reliability.
- Examples: RabbitMQ, Apache Kafka, Amazon SQS.
Event-Driven Architectures
An event-driven architecture is where the flow of the application is determined by events. Components produce and consume events, reacting to changes or actions.
- Characteristics:
- Event Producers: Components that generate events.
- Event Consumers: Components that listen for and react to events.
- Event Bus: The mechanism through which events are transmitted.
- Benefits:
- Scalability: Components can scale independently.
- Flexibility: New event handlers can be added without altering existing components.
- Responsiveness: Immediate reaction to changes or actions.
Data Consistency Models
These models define the rules for how data remains consistent across distributed systems.
- ACID (Atomicity, Consistency, Isolation, Durability): Ensures that transactions are processed reliably. Common in traditional relational databases.
- Atomicity: All parts of a transaction are completed successfully or none are.
- Consistency: The database remains in a consistent state before and after a transaction.
- Isolation: Transactions do not interfere with each other.
- Durability: Once a transaction is committed, it remains so, even in case of failures.
- BASE (Basically Available, Soft state, Eventually consistent): More relaxed model compared to ACID, often used in NoSQL databases.
- Basically Available: The system guarantees the availability of the data.
- Soft State: The state of the system might change over time, even without new input.
- Eventually Consistent: The system will become consistent over time, given no new updates.
- Consistency Models:
- Strong Consistency: Guarantees that after a write, all subsequent reads will return the latest value.
- Eventual Consistency: Guarantees that, given enough time, all replicas of the data will converge to the same value.
- Causal Consistency: Ensures that operations that are causally related are seen by all nodes in the same order.
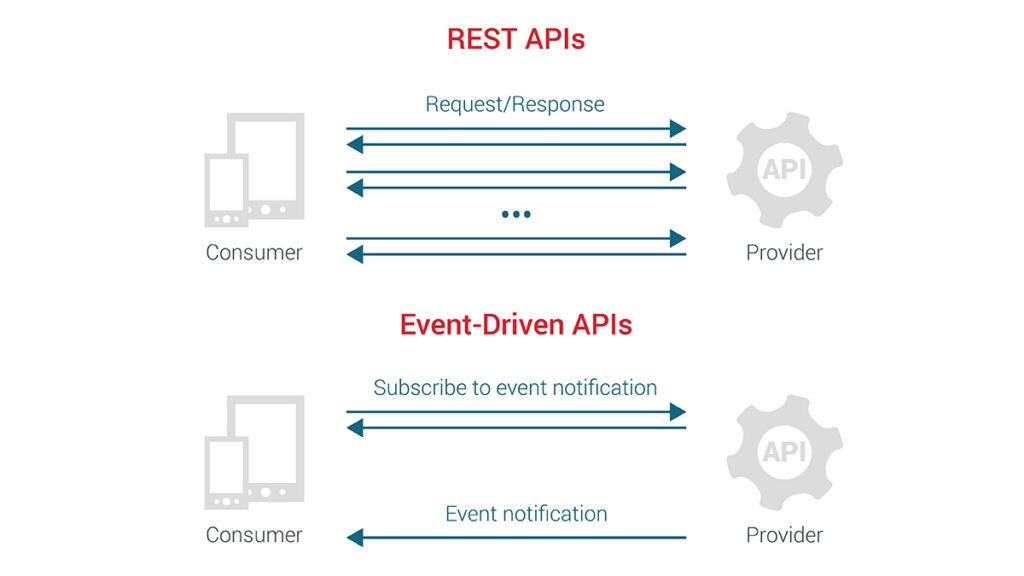
Source: https://blog.axway.com/learning-center/apis/basics/event-driven-vs-rest-api-interactions
Conclusion
System design is more than just a technical discipline; it is a strategic tool that aligns technology with business objectives. By understanding and applying sound system design principles, businesses can improve operational efficiency, enhance customer satisfaction, manage risks, and drive innovation—all of which are key to achieving long-term success in a competitive market.